MULTINOT
Multidimensional Annotation of English-Spanish comparable and parallel texts for linguistic and computational applications
The MULTINOT project aims at the creation of a parallel English-Spanish corpus which is balanced –in terms of register diversity and translation directions– and whose design and enrichment with multidimensional annotations focuses on quality rather than on quantity.
The project offers the scientific community a multifunctional resource which can be used by a variety of potential users and in a number of theoretical and applied contexts, such as, e.g.:
- linguists working on contrastive and corpus-based analysis
- translators in need of bilingual parallel texts in both directions
- translation trainers as a resource for computer-assisted translation
- language teachers and computational linguists developing NLP applications.
The resulting corpus –the MULTINOT corpus– is a one-million-word sentence-aligned, and multidimensionally-annotated parallel corpus for the language pair English-Spanish.
The MULTINOT corpus distinguishes itself from other parallel corpora by having a balanced composition (both in terms of registers and translation directions) and by focusing on quality rather than quantity. Thus, during the data collection phase, we made sure that the text samples were extracted from published online materials provided by publishing houses, press, government, corporate enterprises, European institutions, and other organisations under the ‘fair use’ agreement. Also, during data processing we also focused on corpus quality by manually correcting text samples at different processing stages such as sentence splitting, alignment and part-of-speech tagging. Furthermore, interannotator agreement has been carried out for the manual annotation phase of several higher level features, such as MODALITY, THEMATISATION, RHETORICAL STRUCTURES and PROJECTION.
The corpus currently contains the proportions of texts specified in table 1:
|
MacroRegister |
Sub-register |
Source=> Target |
English |
Spanish |
Total |
|
Literature |
Novels |
EN=>ES |
24886 orig |
26927 trans |
51813 |
|
ES=>EN |
27939 tran |
26672 orig |
54611 |
||
|
Short stories |
EN=>ES |
2186 orig |
2088 trans |
4274 |
|
|
ES=>EN |
1175 orig |
1197 trans |
2372 |
||
|
Essays |
EN=>ES |
27382 orig
|
27235 trans |
54617 |
|
|
ES=>EN |
32517 trans |
30362 orig |
62879 |
||
|
Journalism |
News reporting articles (popsci) |
EN=>ES |
10658 orig |
9753 trans |
20411 |
|
ES=>EN |
24579 orig |
23730 trans |
48309 |
||
|
Administrative |
Official speeches |
EN=>ES |
25373 orig |
27112 trans |
52485 |
|
ES=>EN |
|
|
|
||
|
Proceedings of debates |
EN=>ES |
25620 orig |
26450 trans |
52070 |
|
|
ES=>EN |
27390 orig |
26320 trans |
53710 |
||
|
External communication |
Promotion/advertising brochures
|
EN=>ES |
23695 orig |
27790 trans |
51485 |
|
ES=>EN |
25761 orig |
25367 trans |
51128
|
||
|
Self-presentation documents |
EN=>ES |
|
|
|
|
|
ES=>EN |
31188 orig |
27326 trans |
58514 |
||
|
Scientific texts |
EN=>ES |
42580 orig |
45047 trans |
87627 |
|
|
ES=>EN |
24322 orig |
23430 trans |
47742 |
||
|
Legal procedures |
EN=>ES |
36688 orig
|
38640 trans |
75328 |
|
|
ES=>EN |
23984 orig |
22185 trans |
46169 |
Table 1: Word count distribution of different registers in MULTINOT (June 2015)
All documents are normalized, preprocessed through the LeTs preprocessing pipeline (Van de Kauter et al. 2013) and aligned. Preprocessing includes automatic and manual correction of:
- Multiple POS tags and lemmatization
- Sentence segmentation
- Basic Document structure in TEI XML
In addition, certain subregisters include manual annotation layers of semantic, pragmatic and discourse features, as follows:
- Modality values (epistemic, deontic, dynamic and volitional values and their subtypes)
- Thematic selection and Progression Patterns
- Projection
- Discourse Markers
In order to enable corpus users to query the corpus selecting the texts that fulfill their specific needs, each sample has an accompanying metadata file including text-related and translation-related information. The whole corpus is released in XML format, and made available through a password-protected online interface to be requested from the project"s principal investigator (Dr. Julia Lavid).
Financing body: Spanish Ministry of Economy and Competitiveness (MINECO) for the period: January 2013-Dec. 2015, with an extension until 31st December 2016.
Reference: FFI2012-32201
Principal Investigator (IP): Dr. Julia Lavid López
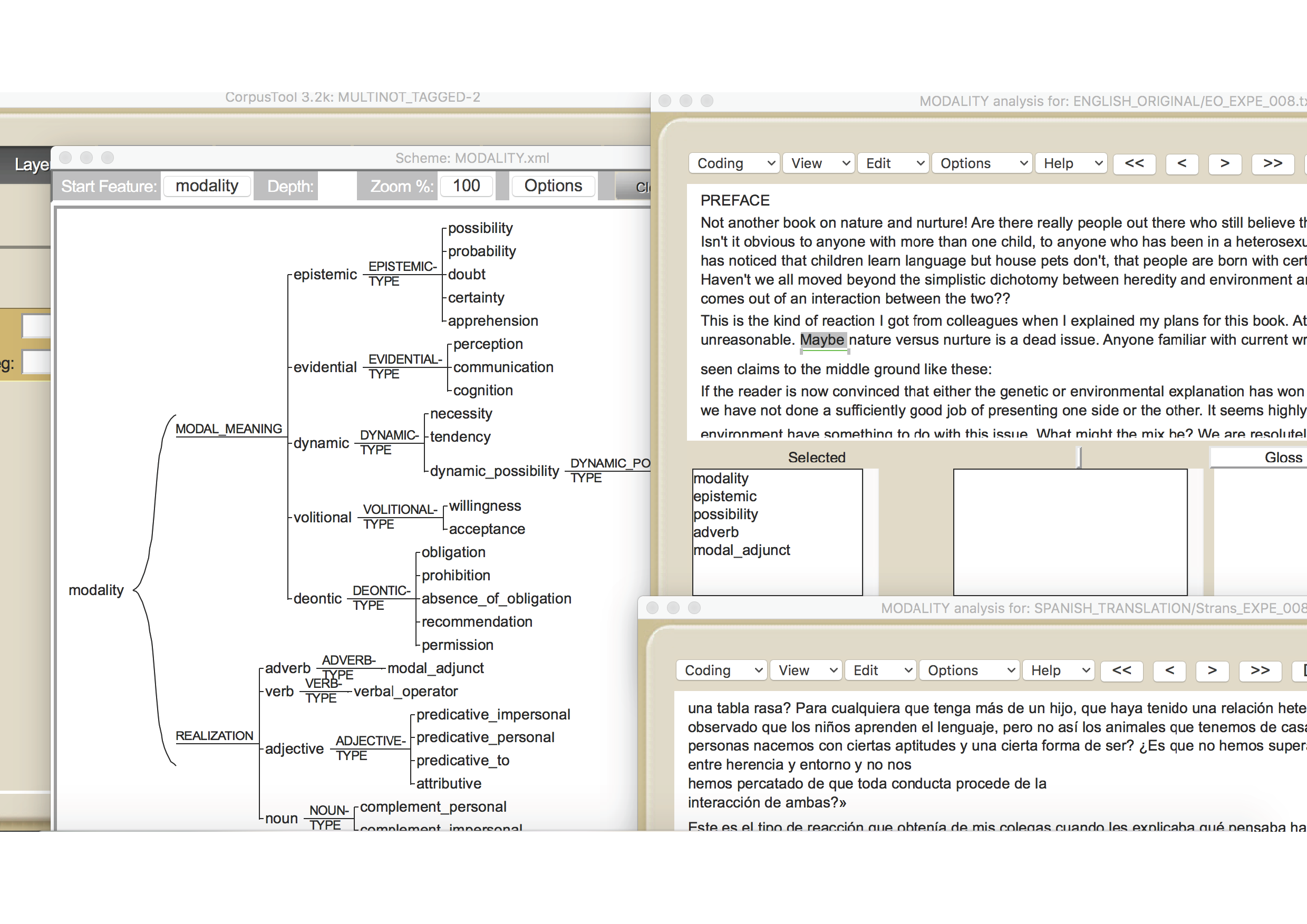
MODALITY meanings and their realisations in English and Spanish
The MODALITY layer provides an analysis of the English original and translated texts, as well as of the Spanish original texts and their translations into Enlgish. The MODAL values which were used and their realisation features are graphically presented in Figure 1 below:
Figure 1: Screenshot of Modality Layer in MULTINOT
Go back to Projects